По результатам нескольких независимых исследований было установлено количественное влияние изменения fillfactor на производительность PostgreSQL при массовых UPDATE операциях.
Для снижения fillfactor на 50% (с 100% до 50%): Основываясь на исследованиях, можно ожидать:
Улучшение производительности UPDATE на 50-70%
Увеличение потребления места на диске вдвое
Снижение производительности SELECT на 20-30% из-за большего количества страниц
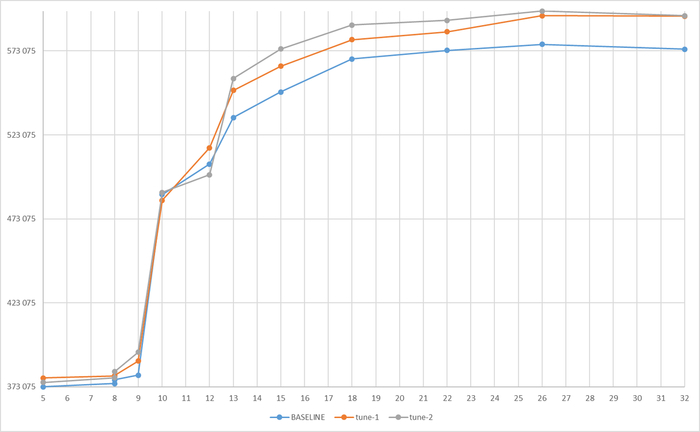
Для данной СУБД , при использовании сценария смешанной нагрузки "Mix", уменьшение значения параметра fillfactor с 100 до 50 дает прирост производительности СУБД:
При нагрузке от 5 до 115 соединений : от -6 до 9%
При нормальной нагрузке(5-22 соединения): от 0 до 9%
Есть сравнительные испытания количесивенногл влияния на производительность изменения fillfactor ?
Ну например - насколько процентов СУБД станет быстрее при массовых update при уменьшении fillfactor на 50%?
прошел день, пока - тишина.
Предположу - ответа не будет. На хабре с обратной связью и плодотворными обсуждениями , дааавно уже не кузяво.
Конечно, было бы очень интересно сравнить с собственными результатами экспериментов. Но в DBA эксперименты вообще не в чести. Как правило камлания, тыкание пальцами в небо и скрижалии от акынов и аксакалов .
Чтобы избежать ситуации - "что-то с памятью моей стало".
Задача
Подготовить базовую формулу расчета для базовой настройки конфигурационных параметров управления памятью для обслуживания СУБД :
shared_buffers
Задаёт объём памяти, который будет использовать сервер баз данных для буферов в разделяемой памяти.
Если вы используете выделенный сервер с объёмом ОЗУ 1 ГБ и более, разумным начальным значением shared_buffers будет 25% от объёма памяти. Существуют варианты нагрузки, при которых эффективны будут и ещё большие значения shared_buffers, но так как Postgres Pro использует и кеш операционной системы, выделять для shared_buffers более 40% ОЗУ вряд ли будет полезно.
maintenance_work_mem
Задаёт максимальный объём памяти для операций обслуживания БД, в частности VACUUM, CREATE INDEX и ALTER TABLE ADD FOREIGN KEY.
autovacuum_work_mem
Задаёт максимальный объём памяти, который будет использовать каждый рабочий процесс автоочистки.
Немного тонкой настройки и СУБД будет работать как часы.
Вопрос нейросети:
Какой параметр для настройки автовакуума для СУБД PostgreSQL эффективнее использовать для очень больших таблиц : autovacuum_vacuum_scale_factor или autovacuum_vacuum_threshold ?
Ответ DeepSeek:
Для очень больших таблиц в PostgreSQL эффективнее использовать параметр autovacuum_vacuum_threshold, а не autovacuum_vacuum_scale_factor. Вот обоснование:
Проблема autovacuum_vacuum_scale_factor для больших таблиц:
Масштабируемость: Формула запуска автовакуума: autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * table_size. По умолчанию: threshold = 50, scale_factor = 0.2 (20%). Для таблицы на 1 млрд строк порог срабатывания: 50 + 0.2 * 1 000 000 000 = 200 000 050 мертвых кортежей. Это приводит к редким запускам и накоплению огромного числа мертвых кортежей.
Риски: Замедление запросов: Длинные таблицы (из-за мертвых кортежей) снижают производительность. Блокировки: Очистка большого объема данных блокирует операции. Срыв транзакций: Если autovacuum не успевает очищать данные до заполнения autovacuum_freeze_max_age.
Почему autovacuum_vacuum_threshold эффективнее?
Фиксированный порог: Позволяет задать абсолютное число мертвых кортежей для запуска (независимо от размера таблицы). Пример: ALTER TABLE big_table SET (autovacuum_vacuum_threshold = 1000000); Автовакуум запустится при достижении 1 млн мертвых кортежей, даже если таблица содержит 1 млрд строк.
Гранулярность: Настройка применяется индивидуально к большим таблицам без влияния на маленькие. Оптимальные значения: от 100 000 до 10 000 000 (зависит от нагрузки и размера).
Рекомендуемая стратегия:
1. Уменьшить scale_factor:
ALTER TABLE big_table SET (autovacuum_vacuum_scale_factor = 0.01); -- 1%
Для таблицы на 1 млрд строк порог: 50 + 0.01 * 1e9 = 10 000 050.
2. Увеличить threshold:
ALTER TABLE big_table SET (autovacuum_vacuum_threshold = 1000000);
Порог: 1 000 000 (фиксированный, без умножения на размер).
3.Комбинировать параметры:
ALTER TABLE big_table SET (autovacuum_vacuum_scale_factor = 0.005, -- 0.5%autovacuum_vacuum_threshold = 500000);
Формула: 500 000 + 0.005 * N.
Дополнительные настройки:
autovacuum_vacuum_cost_limit (увеличить для ускорения):
ALTER TABLE big_table SET (autovacuum_vacuum_cost_limit = 2000); -- вместо 200 по умолчанию
autovacuum_naptime (уменьшить интервал проверок).
Итог:
Для очень больших таблиц:
Основной параметр: autovacuum_vacuum_threshold (фиксированный порог).
Вспомогательный: autovacuum_vacuum_scale_factor (уменьшать до 0.1–0.5%).
Настраивать индивидуально для таблицы через ALTER TABLE.
Мониторить эффективность через представление pg_stat_user_tables (столбцы n_dead_tup и last_autovacuum).
До финиша, сложно предсказать результат. Нужны тесты.
Задача
Провести тестирование методологии для оценки влияния оптимизации конфигурационных параметров СУБД на производительность СУБД.
Общий алгоритм действий и постановка эксперимента
Тестовый прогон нагрузочного тестирования по сценарию смешанной нагрузки с целью определения базовых показателей производительности, характерных ожиданий и нагрузки на СУБД соответствующей максимальной производительности (N_BASE) .
Изменение значений конфигурационных параметров. Нагрузочное тестирование с минимальной нагрузки до нагрузки N_BASE.
Сравнительный анализ изменения производительности и характерных ожиданий СУБД.
Конфигурация виртуальной машины
CPU = 2
RAM = 1GB
Postgres Pro (enterprise certified) 15
Размер тестовой БД = 10GB
Эксперимент-1 : Тестовый прогон при базовых значениях конфигурационных параметров
Какие типы ожидания wait_event_type будут иметь наибольшую корреляцию со снижением производительности СУБД PostgreSQL при выполнении UPDATE для виртуальной машины CPU = 2 и RAM = 2GB при росте нагрузки с 5 до 115 одновременных соединений ?
Ответ нейросети
При анализе корреляции между типами ожиданий (wait_event_type) в PostgreSQL и снижением производительности во время UPDATE на слабой ВМ (2 vCPU, 2 ГБ RAM) при росте нагрузки с 5 до 115 соединений, наибольшую корреляцию будут иметь следующие типы ожиданий, ранжированные по степени влияния:
1. LWLock (Lightweight Locks)
Почему корреляция высокая:
На слабых ВМ (особенно с 2 vCPU) нехватка CPU усиливает конкуренцию за системные ресурсы.
LWLock защищает внутренние структуры данных (буферы, память, lock-менеджер). При высокой нагрузке (115 соединений) процессы блокируются в очередях на эти ресурсы.
Подтипы buffer_content, buffer_mapping, lock_manager будут доминировать из-за частого доступа к буферам и блокировкам.
Связь с производительностью: Прямая корреляция с ростом времени ожидания и снижением TPS (transactions per second).
2. Lock (Транзакционные блокировки)
Почему корреляция высокая:
UPDATE вызывает эксклюзивные блокировки строк (ROW SHARE/EXCLUSIVE).
При 115 соединениях конкуренция за одни строки/таблицы резко возрастает → частые ожидания снятия блокировок.
Возникает при ожидании доступа к буферу данных, удерживаемому другим процессом.
Усиливается при нехватке RAM и высокой конкуренции за буферы.
Менее критичен, чем LWLock/Lock, но значим при массовых UPDATE.
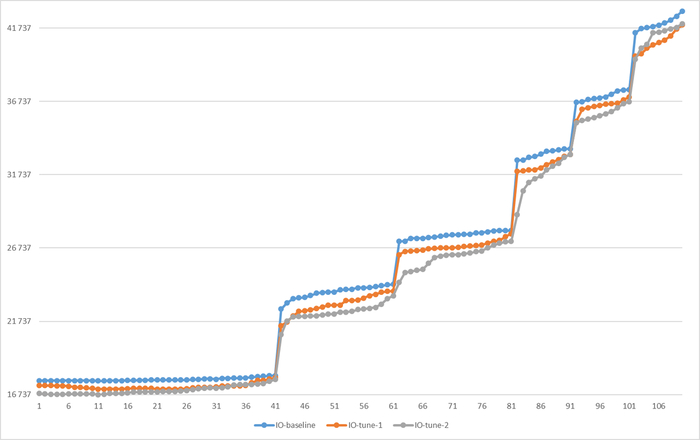
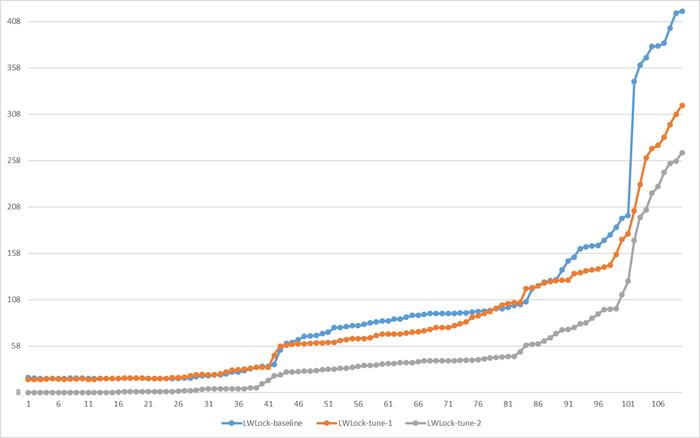
Итог: Наибольший вклад в снижение производительности внесут LWLock и Lock из-за нехватки CPU/RAM и высокой конкуренции. IO станет критичным при исчерпании буферного кеша.
Как обстоит ситуация в реальности :
Результаты
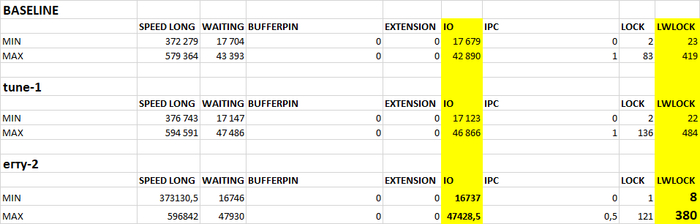
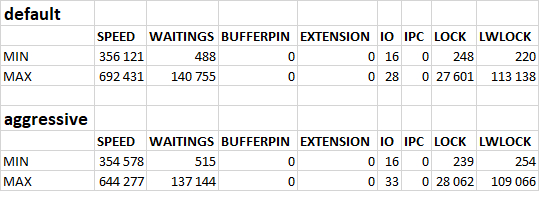
Для данного сценария "Update only"и данной конфигурации СУБД характерными значениями корреляции между ожиданиями СУБД и типами ожиданий , являются :
IO : сильная отрицательная корреляция , влияние ожиданий типа IO на производительность СУБД отсутствует.
IPC : ожидания практически отсутствуют, влияние на производительность СУБД отсутствует.
Lock : очень сильная прямая корреляция, сильное влияние ожиданий типа Lock на снижение производительности СУБД .
LWLock : слабая отрицательная корреляция , влияние ожиданий типа LWLock на производительность СУБД отсутствует.
В принципе - ничего неожиданного. Наивно было бы ожидать от алгоритма статистической обработки текстов в интернете исследований и логических выводов, тем более в отсутствии материалов и результатов реальных экспериментов.
Очередная иллюстрация -ЛЮБОЙ ответ нейросетей необходимо экспериментально проверять.
В случае использования советов нейросетей - древняя мудрость особенно актуальна.
Вопрос DeepSeek
Как изменится производительность СУБД PostgreSQL при нагрузке создаваемой pgbench и количестве подключений от 5 до 100 для СУБД размером 300MB при ресурсах CPU = 2 и RAM = 2GB при изменении настроек автовакуума с настроек по умолчанию на агрессивные настройки ?
Ответ DeepSeek
Исходные параметры:
Размер БД: 300 MB
Ресурсы: 2 CPU, 2 GB RAM
Количество подключений: 5–100
Нагрузка: pgbench в режиме TPC-B (смесь SELECT/UPDATE).
Сравнение: Настройки по умолчанию:
autovacuum_vacuum_scale_factor = 0.2
autovacuum_vacuum_threshold = 50
autovacuum_vacuum_cost_delay = 20ms
autovacuum_vacuum_cost_limit = 200
Агрессивные настройки:
autovacuum_vacuum_scale_factor = 0.05 # Запуск при 5% изменений вместо 20%
autovacuum_vacuum_threshold = 25 # Нижний порог срабатывания
autovacuum_vacuum_cost_delay = 5ms # Меньшая задержка между операциями
autovacuum_vacuum_cost_limit = 1000 # Больше операций за один проход
Прогнозируемые результаты:
1. Низкая нагрузка (5–20 подключений):
По умолчанию: Автовакуум запускается редко. Мертвые кортежи накапливаются, но не критично. Производительность стабильна. TPS: ~600–800.
Агрессивные настройки: Автовакуум срабатывает чаще, но нагрузка от него незначительна. Мертвые кортежи удаляются своевременно. TPS: ~650–850 (+5–10%).
2. Средняя нагрузка (30–60 подключений):
По умолчанию: Накопление мертвых кортежей приводит к: Увеличению размера таблиц (из-за "раздувания"). Замедлению SELECT (сканирование большего объема данных). Блокировкам при UPDATE из-за долгих вакуумных операций. TPS: падение до 400–500.
Агрессивные настройки: Частые, но короткие вакуум-сессии. Меньше "раздувания", быстрее доступ к данным. TPS: ~550–700 (+20–40%).
3. Высокая нагрузка (80–100 подключений):
По умолчанию: Критическое накопление мертвых кортежей. Автовакуум не успевает очищать данные, что вызывает: Резкое падение TPS (до 200–300). Рост времени отклика (блокировки, конкуренция за I/O).
Агрессивные настройки: Плюсы: Минимизация "раздувания", стабильный TPS (~450–600). Минусы: Конкуренция за ресурсы CPU между фоновым вакуумом и рабочими процессами. При 2 CPU возможны просадки из-за нехватки вычислительной мощности.
Ключевые метрики для сравнения:
TPS (Transactions Per Second): Агрессивные настройки дадут прирост на 20–40% при 30–60 подключениях. При 80–100 подключениях рост TPS будет менее значительным (+10–15%) из-за ограничений CPU.
Задержки (Latency): В агрессивном режиме задержки будут стабильнее, особенно в диапазоне 30–60 подключений.
Размер таблиц (Table Bloat): Агрессивный автовакуум уменьшит "раздувание" на 40–60% по сравнению с настройками по умолчанию.
Использование CPU: При агрессивных настройках нагрузка на CPU вырастет на 15–25% из-за частого выполнения вакуума.
Рекомендации:
Для тестовой конфигурации (2 CPU, 2 GB RAM): Агрессивные настройки целесообразны при 20–60 подключениях. При 80–100 подключениях требуется мониторинг CPU: если загрузка достигнет 90–100%, производительность может ухудшиться.
Оптимизация под высокую нагрузку: Увеличьте autovacuum_max_workers (если нужно параллелить вакуум). Настройте maintenance_work_mem (выделите 256–512 MB для операций вакуума).
Дисковый I/O: Если диск медленный (HDD), агрессивный автовакуум может вызвать contention I/O. Используйте SSD для минимизации рисков.
Заключение:
Агрессивные настройки автовакуума улучшат производительность на 20–40% при 30–60 подключениях, предотвращая "раздувание" таблиц. Однако при экстремальной нагрузке (80–100 подключений) и ограниченных ресурсах CPU (2 ядра) возможна конкуренция за процессорное время, что снизит эффективность. Тестирование на реальной инфраструктуре с мониторингом CPU/I/O обязательно.
Результаты сравнительных экспериментов
Конфигурация виртуальной машины
CPU = 2RAM = 2GB
Версия СУБД:Postgres Pro (enterprise certified) 15.8.1 on x86_64-pc-linux-gnu, compiled by gcc (AstraLinuxSE 8.3.0-6) 8.3.0, 64-bit
Ноутбуки используют не только для работы: на них смотрят сериалы, редактируют фото, запускают игры и монтируют ролики. Поэтому теперь требования к устройству такие: быть легким для дороги, надежным для горящих дедлайнов и стильным, чтобы не прятать в переговорке. А еще — легко работать в связке с другими гаджетами.
Протестировали TECNO MEGABOOK K15S вместе со смартфоном TECNO CAMON 40 и наушниками TECNO в рабочих и бытовых сценариях от Zoom-звонков до перелета, а теперь рассказываем, как себя показала техника.
Первое впечатление от дизайна ноутбука
Первое, что заметно — это вес. При диагонали 15,6 дюйма и полностью металлическом корпусе K15S весит всего 1,7 кг. Это примерно на 15% меньше, чем аналоги. Устройство не обременяет ни в офисе, ни в такси. Ноутбук поместился в стандартный городской рюкзак, было удобно достать его в кафе за завтраком и по дороге в такси, чтобы быстро отработать клиентские правки.
1/4
Дизайн сдержанный, без ярких акцентов, с матовой поверхностью. Правда, на ней остаются следы от рук. Так что если приходится постоянно открывать ноутбук в присутствии клиентов или партнеров, лучше купить прозрачный кейс. Визуально и тактильно устройство ощущается надежно: не выскальзывает и не двигается по столу, благодаря специальным резиновым накладкам на задней части.
Шарнир работает мягко: чтобы открыть крышку даже одной рукой, не нужно придерживать корпус. Чтобы показать коллеге или клиенту презентацию, достаточно раскрыть экран на 180°. Это удобно и для работы лежа, и для подставок, которые требуют определенного угла обзора.
Также отметим 9 портов: USB-A, USB-C, HDMI, слот для карты памяти — можно забыть о переходниках.
В TECNO MEGABOOK K15S предустановлен Windows 11. Ноутбук готов к работе сразу после включения. Никаких лишних установок и обновлений. Все настроено и оптимизировано для вашей многозадачности.
Экран: яркая картинка и комфорт ночью
Экран — 15,6 дюйма, IPS-матрица с разрешением Full HD. Углы обзора отличные: изображение остается четким, даже если смотреть сбоку, цвета не искажаются. Есть антибликовое покрытие. Тестировали ноутбук при разном освещении: можно спокойно работать у окна. Когда солнце бьет прямо в экран, текст по-прежнему остается читаемым, картинки не искажаются. Это редкость в бюджетных моделях.
1/2
Неважно, работаете вы ночью или играете, выручит клавиатура с регулируемой четырехуровневой подсветкой. При среднем уровне в темноте все видно, глаза не устают. Из плюсов для тревожных людей: включали ноутбук в самолете и электричке, никто вокруг не жаловался на яркость. Все регулируется кнопками, не нужно лишний раз заходить в настройки.
Стеклокерамический крупный тачпад — 15 см. Он не залипает, не промахивается, срабатывает с первого касания. Не возникает дискомфорта, даже если несколько часов редактировать документы без мышки. После перехода с других устройств немного непривычно, что тачпад работает в двух направлениях: нижняя часть отзывается нажатием, верхняя — касанием.
В кнопку питания встроен сканер отпечатка пальцев. К нему можно быстро привыкнуть, особенно если сидишь в опенспейсе или работаешь в дороге. Один легкий тап пускает в систему даже с мокрыми руками. Безопасно, удобно и не нужно постоянно вводить пароли.
Ноутбук работает на AMD Ryzen 7 5825U (опционально можно выбрать версию техники Intel Core i5-13420H). Восьмиядерный AMD с поддержкой 16 потоков подходит для ресурсоемких операций вроде рендеринга или работы с большими массивами данных. Встроенная графика Radeon справляется с редактированием видео в Full HD или играми.
1/4
Во время монтажа 30-минутного ролика в DaVinci Resolve и параллельной работе в Photoshop с несколькими большими PSD-файлами система сохраняла стабильность. Не было ни зависаний, ни заметного падения производительности. Ноутбук уверенно держит в фоне 10 приложений одновременно. Если запущены браузер с 20 вкладками, видеозвонок в Telegram, Excel с объемной таблицей и софт для монтажа, система не тормозит и не перегревается. Переход между окнами остается плавным, ничего не «проседает», даже при одновременном скачивании файлов и редактировании видео.
Базовая комплектация включает 16 ГБ оперативной памяти в двух слотах. При необходимости можно легко увеличить этот показатель до 32 ГБ, заменив стандартные модули на более емкие. Помимо установленного SSD на 1 ТБ предусмотрен дополнительный слот, поддерживающий диски объемом до 2 ТБ.
Чтобы во время нагрузки системы охлаждения не выходили из строя, в ноутбук встроен эффективный вентилятор, способный рассеивать до 35 Вт тепла. Устройство не греется, его спокойно можно держать на коленях. Это решение дополнено тремя режимами работы, которые переключаются простой комбинацией клавиш Ctrl+Alt+T. Тихий режим идеален для работы ночью или в общественных местах, сбалансированный подходит для повседневных задач. Производительный, на котором запускали рендеринг видео и игры, практически не шумит.
Автономность: 15 часов без подзарядки
Протестили автономность MEGABOOK K15S в условиях, знакомых каждому деловому путешественнику. Утром перед вылетом зарядили ноутбук до 100% и взяли его в рейс Москва — Калининград. В зале ожидания провели созвон, потом три часа смотрели сериал и в дороге до отеля редактировали документы. К моменту приезда оставалось 40% заряда: хватило бы еще на пару часов продуктивной работы.
1/3
MEGABOOK K15S может автономно работать до 15 часов и позволяет не оглядываться на индикатор заряда. Заявленное время достигается при типичном офисном использовании: одновременная работа с документами в Word и Excel, ведение переписки, видеоконференции, веб-серфинг.
Если все же понадобится, за час восполняется до 70% батареи. Компактный адаптер мощностью 65 Вт на базе нитрида галлия поместился даже в карман пиджака. Один блок питания заряжает и ноутбук, и смартфон, и наушники. Экономия места: не нужно никаких дополнительных проводов.
Звук, который реально слышно
В TECNO MEGABOOK K15S установлены два мощных динамика по 2.5 Вт. Звук с глубокими низами, без пластикового дребезжания, объемный. Благодаря DTS можно смотреть видео даже в шумном помещении. В тестах специально включали сцены с шагами и выстрелами: локализация настолько точная, что в наушниках нет необходимости.
Та же стабильность и в микрофоне. Благодаря AI-шумоподавлению голос передается чисто. Во время тестовых звонков из оживленного кафе собеседник не услышал ни разговоры за соседним столом, ни городской шум. И все это — на расстоянии до пяти метров.
Кстати, о созвонах. В ноутбуке встроена обновленная камера. Она отслеживает положение лица, а еще есть физическая шторка приватности. Например, можно закрыть шторку для комфортных видеоконференций.
Для тех, кто предпочитает гарнитуру, идеально подойдут беспроводные наушники TECNO FreeHear 1 из экосистемы бренда. Когда не хотелось делиться разговорами с окружающими, подключали их. Чистый звук с акцентом на средние частоты, 11-мм драйверы, которые выдают неожиданную детализацию. Музыку слушать приятно: и фоновый плейлист на телефоне, и вечерний сериал на ноутбуке. Автономно работают наушники 6 часов, с кейсом — до 30 часов.
1/2
Bluetooth 5.4 обеспечивает стабильное соединение на расстоянии до 10 метров. Удобная C-образная форма разработана специально для длительного ношения — после восьмичасового рабочего дня в ушах не возникает дискомфорта. Наушники поддерживают одновременное подключение к ноутбуку и смартфону. Переключение между устройствами происходит быстро и без заминок.
Через фирменное приложение Welife можно выбрать один из четырех эквалайзеров и отследить местоположение гарнитуры в случае утери. А еще кастомизировать виджет для управления наушниками. Функция настройки персонализированного дизайна доступна для устройств на Android и позволяет гибко изменить внешний вид окна подключения: вплоть до установки фоновой картинки или собственного фото.
Первые пару использований может потребоваться время, чтобы привыкнуть к нестандартной форме вкладышей, но уже с третьего раза они надеваются вслепую за секунду. Что особенно приятно: собеседники отмечают, что звук от микрофона более приятный и четкий, чем у дорогих известных моделей.
Бесшовная синхронизация со смартфоном
Благодаря функции OneLeap ноутбук синхронизируется со смартфоном TECNO. Подключение происходит за пару секунд: достаточно один раз подтвердить сопряжение. После этого открывается доступ к бесшовному переключению между устройствами — объединенному буферу обмена, дублированию экранов и передаче файлов без кабелей и пересылок в мессенджерах.
Функция выручила, когда нужно было открыть приложение, у которого нет веб-версии. Удобно работает и буфер обмена: скопировал текст на одном устройстве — вставил на другом. Например, код, полученный в сообщении на телефоне, вводится в браузере на ноутбуке. Экономит минуты, а иногда и нервы. А когда в дороге пропал Wi-Fi, ноутбук сам подключился к мобильному интернету через смартфон.
1/2
TECNO CAMON 40 и сам по себе — мощный рабочий инструмент. Смартфон выделяется камерой высокого качества 50 Мп, ярким AMOLED-экраном 120 Гц и множеством функций, которые упрощают процесс мобильной съёмки и использование искусственного интеллекта TECNO AI.
Телефон работает на HIOS 15.0.1 на базе Android 15.В фирменную оболочку встроен искусственный интеллект:
Голосовой помощник Ella. Отвечает на вопросы, помогает с задачами и управлением устройством.
Решение задач. Наводите камеру на задачу, ИИ решает ее.
AI Редактор фотографий. Интеллектуальная обработка в одно касание.
Быстрый поиск. Находит адрес на экране и запускает навигацию, распознает объекты и события, автоматически добавляет их в календарь.
1*USB-A 3.2, 1*3.5mm аудиовход, *Ethernet RJ45 до 1 Гбит, 2*Туре-С (Full Function), 1*слот для замка Kensington.
Другое. Сканер отпечатка пальца в кнопке питания. Клавиатура с подсветкой (4 уровня яркости). Тачпад с поддержкой одновременно 4 касаний.
Батарея. 70 Вт∙ч (6150 мА∙ч), Li-Pol, 11.55 B 65 Вт Type-C GaN, 20 В, 3.25 А, кабель 1.8 м (Туре-С-Type-C).
Габариты. 17.3 мм (высота), 359.5 мм (ширина), 236 мм (глубина).
Вес. 1,7 кг.
Если хотите создать собственную экосистему, в которой технологии подстроятся под ритм дня, попробуйте технику TECNO. Мощный ноутбук, быстрый смартфон и наушники соединяются в единое пространство. Быстрое переключение между устройствами, синхронизация файлов и стабильное соединение без лишних настроек.
Как обычно , для развлечения задал вопрос нейросетям : Как размер тестовой базы данных pgbench влияет на производительность СУБД при проведении нагрузочного тестирования с использованием pgbench в качестве инструмента создания нагрузки ?
Ответ YandexGPT:
При проведении нагрузочного тестирования с использованием pgbench размер тестовой базы данных играет ключевую роль в определении производительности СУБД. Вот основные аспекты, которые следует учитывать:
Инициализация тестовой базы:
Инструмент pgbench позволяет инициализировать тестовую базу с определенным масштабом, используя параметр --scale=количество. Например, --scale=4000 задает базу размером 4000 записей.
Влияние размера базы на производительность:
Больше данных — ниже производительность: Увеличение размера базы данных может привести к снижению производительности, так как большее количество данных требует больше времени на обработку транзакций.
Кэширование: Если база данных помещается в кэш СУБД, операции могут выполняться быстрее за счет уменьшения времени доступа к диску. Однако при превышении объема кэша производительность может значительно упасть.
Внешние ключи и соединения:
При инициализации базы можно использовать параметр --foreign-keys для включения внешних ключей, что усложняет схему данных и может повлиять на время выполнения запросов.
Параметры нагрузки:
Нагрузочное тестирование с pgbench обычно включает циклы нагрузок с переменным числом клиентов (например, 1, 10, 20, 50, 100) в течение заданного времени (например, 600 секунд с параметром -T 600).
Результаты тестирования логируются в отдельные файлы, что позволяет строить графики зависимости показателей (например, транзакций в секунду или средней задержки) от числа клиентов.
Дополнительные метрики:
Помимо основных показателей, таких как TPS (транзакций в секунду), полезно отслеживать среднюю задержку (Latency average), которая показывает время выполнения транзакций.
Автоматизация с pg_perfbench:
Для точного фиксирования всех деталей окружения и результатов тестирования рекомендуется использовать инструмент pg_perfbench. Он автоматизирует сбор системной информации и генерацию отчетов, что упрощает сопоставление и анализ результатов различных тестов.
Таким образом, размер тестовой базы данных существенно влияет на производительность СУБД при нагрузочном тестировании с использованием pgbench. Увеличивая размер базы, можно наблюдать снижение производительности из-за роста времени обработки данных. Важно учитывать все параметры конфигурации и детали окружения для точного анализа и воспроизводимости тестов.
Ответ ChatPPG:
Размер тестовой базы данных может существенно влиять на результаты тестирования с использованием pgbench. Вот несколько ключевых моментов, которые стоит учесть:
1. **Коэффициент масштаба (-s)**: - Параметр -s (или --scale) позволяет умножить количество строк в таблицах на заданный коэффициент. Например, с ключом -s 100 в таблицу pgbench_accounts будет записано 10 000 000 строк. - Более крупные базы данных могут потребовать больше времени на выполнение операций вставки, обновления и выборки, что может повлиять на общую производительность и количество транзакций в секунду (TPS).
2. Размер таблиц и индексов: - Большие таблицы и индексы могут увеличивать время выполнения запросов из-за увеличения времени поиска и обновления данных. - В больших базах данных могут возникать дополнительные задержки из-за увеличения объема данных, которые нужно обрабатывать.
3. Память и кэширование: - В больших базах данных может быть меньше данных, которые умещаются в памяти, что приводит к увеличению количества операций ввода-вывода (I/O) и замедлению производительности. - Кэширование данных в памяти может быть менее эффективным, что также может сказаться на результатах тестирования.
4. Примеры результатов тестирования: - В документации [pg_stat_statements](https://postgrespro.com/docs/postgresql/15/pgstatstatements#...) приведены примеры результатов тестирования с использованием pgbench. Например, при выполнении 300 транзакций с 10 клиентами можно увидеть, что время выполнения запросов может значительно различаться в зависимости от размера базы данных и количества операций.
Пример команды для инициализации базы данных с коэффициентом масштаба 10: pgbench -i -s 10 bench
Пример команды для запуска тестирования с 10 клиентами и 300 транзакциями: pgbench -c 10 -t 300 bench
Таким образом, увеличение размера тестовой базы данных может привести к снижению производительности и количества транзакций в секунду, что важно учитывать при настройке и интерпретации результатов тестирования с использованием pgbench.
Как обычно , в рассуждениях нейросети есть 2 принципиально слабых момента: 1-У нейросети нет результатов экспериментов и никаких фактов , только статистическая обработка текстов документации. 2-Нейросеть , в принципе не способна логически рассуждать , и не знает , что рост размера тестовой базы данных приводит к снижению количества тяжелых блокировок при выполнении update.
P.S. А вот ответ DeepSeek удивил, полнотой ответа и упоминанием влияния конкурентного обновления .
Размер тестовой базы данных в pgbench существенно влияет на производительность СУБД PostgreSQL во время нагрузочного тестирования. Вот основные аспекты этого влияния:
### 1. **Кеширование данных в памяти** - **Маленькая база**: Если данные полностью помещаются в кеш (например, в `shared_buffers` или оперативной памяти), операции чтения выполняются быстрее, так как минимизируются обращения к диску. Это увеличивает TPS (транзакций в секунду) и снижает задержки. - **Большая база**: При превышении объема данных над доступной памятью возникают промахи кеша, что приводит к частым чтениям с диска. Это замедляет выполнение запросов, особенно для операций `SELECT`.
### 2. **Конфликты доступа (Contention)** - **Маленькая база**: Выше вероятность конфликтов при параллельных обновлениях (например, в таблицах `accounts`). Это увеличивает время ожидания блокировок и снижает пропускную способность. - **Большая база**: Данные распределены по большему числу строк, что снижает конкуренцию за одни и те же записи. Это особенно важно для тестов с высокой долей операций `UPDATE`.
### 3. **Планирование запросов** - На маленьких базах статистика, собираемая PostgreSQL, может быть недостаточно репрезентативной, что приводит к неоптимальным планам выполнения запросов (например, выбор полного сканирования вместо использования индекса). - На больших базах оптимизатор чаще выбирает эффективные планы, так как статистика точнее отражает распределение данных.
### 4. **Нагрузка на подсистему ввода-вывода (I/O)** - При больших размерах базы возрастает нагрузка на диск из-за: - Чтения данных, не помещающихся в кеш. - Записи WAL (Write-Ahead Log) и выполнения checkpoint’ов, которые требуют больше времени. - Это может стать узким местом для write-heavy нагрузок.
### 5. **Эффективность индексов** - Большие индексы (например, в таблице `accounts`) требуют больше ресурсов для обновления и поиска. Если они не помещаются в память, производительность снижается.
### 6. **Фоновые процессы** - **Checkpoint**: На больших базах checkpoint’ы выполняются дольше, что может вызывать всплески нагрузки на диск. - **Autovacuum**: Чаще срабатывает на больших базах, конкурируя с рабочими транзакциями за ресурсы.
### Примеры сценариев - **Read-only тесты**: - Маленькая база: Высокий TPS из-за кеширования. - Большая база: Снижение TPS, если данные не помещаются в память. - **Write-heavy тесты**: - Маленькая база: Риск contention и частые блокировки. - Большая база: Меньше конфликтов, но выше нагрузка на WAL и диск.
### Рекомендации - Выбирайте размер базы, сопоставимый с реальными данными, чтобы тесты отражали эксплуатационные условия. - Для тестирования предельной производительности в идеальных условиях используйте базу, которая помещается в память. - Чтобы оценить работу с диском, задайте размер базы, превышающий доступную память. - Увеличивайте масштабный фактор (`-s`) постепенно, анализируя, как меняется производительность.
### Заключение Оптимальный размер тестовой базы зависит от целей тестирования. Для оценки максимальной производительности подходит маленькая база, а для имитации реальной нагрузки — база, сопоставимая с продакшеном по объему и структуре.