Чтобы избежать ситуации - "что-то с памятью моей стало".
Задача
Подготовить базовую формулу расчета для базовой настройки конфигурационных параметров управления памятью для обслуживания СУБД :
shared_buffers
Задаёт объём памяти, который будет использовать сервер баз данных для буферов в разделяемой памяти.
Если вы используете выделенный сервер с объёмом ОЗУ 1 ГБ и более, разумным начальным значением shared_buffers будет 25% от объёма памяти. Существуют варианты нагрузки, при которых эффективны будут и ещё большие значения shared_buffers, но так как Postgres Pro использует и кеш операционной системы, выделять для shared_buffers более 40% ОЗУ вряд ли будет полезно.
maintenance_work_mem
Задаёт максимальный объём памяти для операций обслуживания БД, в частности VACUUM, CREATE INDEX и ALTER TABLE ADD FOREIGN KEY.
autovacuum_work_mem
Задаёт максимальный объём памяти, который будет использовать каждый рабочий процесс автоочистки.
Немного тонкой настройки и СУБД будет работать как часы.
Вопрос нейросети:
Какой параметр для настройки автовакуума для СУБД PostgreSQL эффективнее использовать для очень больших таблиц : autovacuum_vacuum_scale_factor или autovacuum_vacuum_threshold ?
Ответ DeepSeek:
Для очень больших таблиц в PostgreSQL эффективнее использовать параметр autovacuum_vacuum_threshold, а не autovacuum_vacuum_scale_factor. Вот обоснование:
Проблема autovacuum_vacuum_scale_factor для больших таблиц:
Масштабируемость: Формула запуска автовакуума: autovacuum_vacuum_threshold + autovacuum_vacuum_scale_factor * table_size. По умолчанию: threshold = 50, scale_factor = 0.2 (20%). Для таблицы на 1 млрд строк порог срабатывания: 50 + 0.2 * 1 000 000 000 = 200 000 050 мертвых кортежей. Это приводит к редким запускам и накоплению огромного числа мертвых кортежей.
Риски: Замедление запросов: Длинные таблицы (из-за мертвых кортежей) снижают производительность. Блокировки: Очистка большого объема данных блокирует операции. Срыв транзакций: Если autovacuum не успевает очищать данные до заполнения autovacuum_freeze_max_age.
Почему autovacuum_vacuum_threshold эффективнее?
Фиксированный порог: Позволяет задать абсолютное число мертвых кортежей для запуска (независимо от размера таблицы). Пример: ALTER TABLE big_table SET (autovacuum_vacuum_threshold = 1000000); Автовакуум запустится при достижении 1 млн мертвых кортежей, даже если таблица содержит 1 млрд строк.
Гранулярность: Настройка применяется индивидуально к большим таблицам без влияния на маленькие. Оптимальные значения: от 100 000 до 10 000 000 (зависит от нагрузки и размера).
Рекомендуемая стратегия:
1. Уменьшить scale_factor:
ALTER TABLE big_table SET (autovacuum_vacuum_scale_factor = 0.01); -- 1%
Для таблицы на 1 млрд строк порог: 50 + 0.01 * 1e9 = 10 000 050.
2. Увеличить threshold:
ALTER TABLE big_table SET (autovacuum_vacuum_threshold = 1000000);
Порог: 1 000 000 (фиксированный, без умножения на размер).
3.Комбинировать параметры:
ALTER TABLE big_table SET (autovacuum_vacuum_scale_factor = 0.005, -- 0.5%autovacuum_vacuum_threshold = 500000);
Формула: 500 000 + 0.005 * N.
Дополнительные настройки:
autovacuum_vacuum_cost_limit (увеличить для ускорения):
ALTER TABLE big_table SET (autovacuum_vacuum_cost_limit = 2000); -- вместо 200 по умолчанию
autovacuum_naptime (уменьшить интервал проверок).
Итог:
Для очень больших таблиц:
Основной параметр: autovacuum_vacuum_threshold (фиксированный порог).
Вспомогательный: autovacuum_vacuum_scale_factor (уменьшать до 0.1–0.5%).
Настраивать индивидуально для таблицы через ALTER TABLE.
Мониторить эффективность через представление pg_stat_user_tables (столбцы n_dead_tup и last_autovacuum).
До финиша, сложно предсказать результат. Нужны тесты.
Задача
Провести тестирование методологии для оценки влияния оптимизации конфигурационных параметров СУБД на производительность СУБД.
Общий алгоритм действий и постановка эксперимента
Тестовый прогон нагрузочного тестирования по сценарию смешанной нагрузки с целью определения базовых показателей производительности, характерных ожиданий и нагрузки на СУБД соответствующей максимальной производительности (N_BASE) .
Изменение значений конфигурационных параметров. Нагрузочное тестирование с минимальной нагрузки до нагрузки N_BASE.
Сравнительный анализ изменения производительности и характерных ожиданий СУБД.
Конфигурация виртуальной машины
CPU = 2
RAM = 1GB
Postgres Pro (enterprise certified) 15
Размер тестовой БД = 10GB
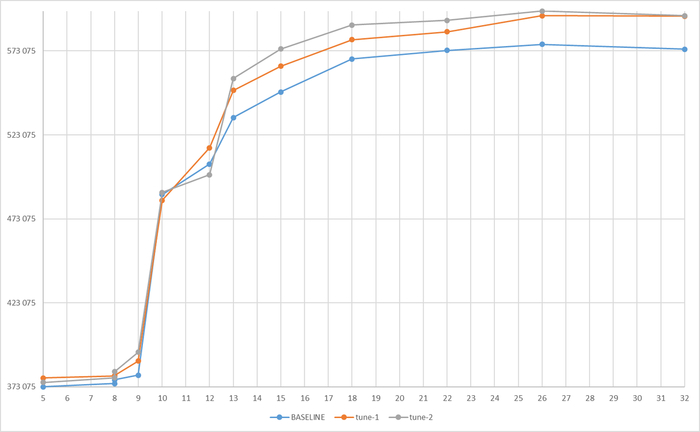
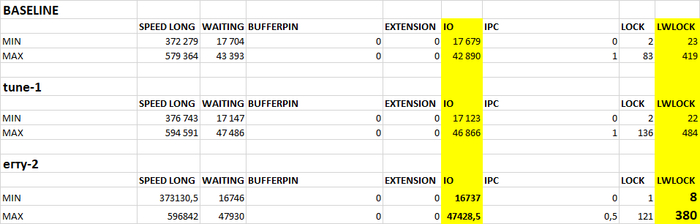
Эксперимент-1 : Тестовый прогон при базовых значениях конфигурационных параметров
Какие типы ожидания wait_event_type будут иметь наибольшую корреляцию со снижением производительности СУБД PostgreSQL при выполнении UPDATE для виртуальной машины CPU = 2 и RAM = 2GB при росте нагрузки с 5 до 115 одновременных соединений ?
Ответ нейросети
При анализе корреляции между типами ожиданий (wait_event_type) в PostgreSQL и снижением производительности во время UPDATE на слабой ВМ (2 vCPU, 2 ГБ RAM) при росте нагрузки с 5 до 115 соединений, наибольшую корреляцию будут иметь следующие типы ожиданий, ранжированные по степени влияния:
1. LWLock (Lightweight Locks)
Почему корреляция высокая:
На слабых ВМ (особенно с 2 vCPU) нехватка CPU усиливает конкуренцию за системные ресурсы.
LWLock защищает внутренние структуры данных (буферы, память, lock-менеджер). При высокой нагрузке (115 соединений) процессы блокируются в очередях на эти ресурсы.
Подтипы buffer_content, buffer_mapping, lock_manager будут доминировать из-за частого доступа к буферам и блокировкам.
Связь с производительностью: Прямая корреляция с ростом времени ожидания и снижением TPS (transactions per second).
2. Lock (Транзакционные блокировки)
Почему корреляция высокая:
UPDATE вызывает эксклюзивные блокировки строк (ROW SHARE/EXCLUSIVE).
При 115 соединениях конкуренция за одни строки/таблицы резко возрастает → частые ожидания снятия блокировок.
Возникает при ожидании доступа к буферу данных, удерживаемому другим процессом.
Усиливается при нехватке RAM и высокой конкуренции за буферы.
Менее критичен, чем LWLock/Lock, но значим при массовых UPDATE.
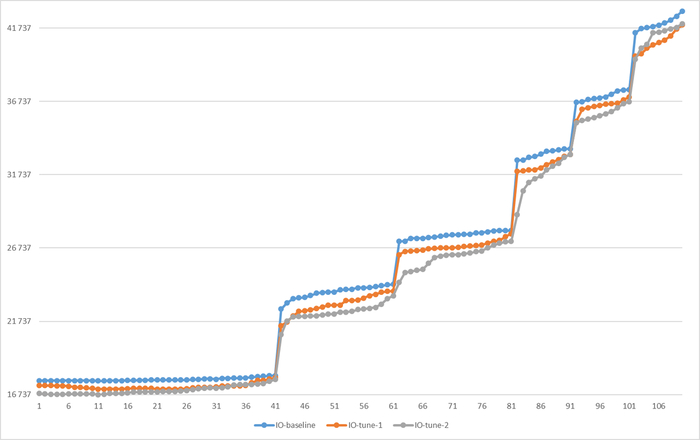
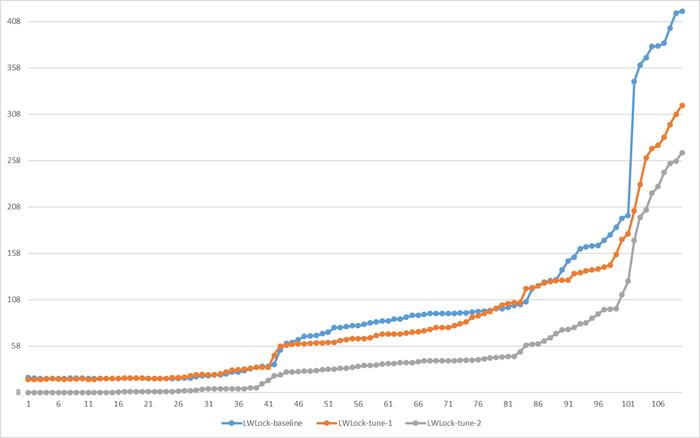
Итог: Наибольший вклад в снижение производительности внесут LWLock и Lock из-за нехватки CPU/RAM и высокой конкуренции. IO станет критичным при исчерпании буферного кеша.
Как обстоит ситуация в реальности :
Результаты
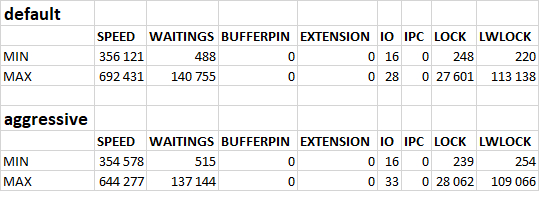
Для данного сценария "Update only"и данной конфигурации СУБД характерными значениями корреляции между ожиданиями СУБД и типами ожиданий , являются :
IO : сильная отрицательная корреляция , влияние ожиданий типа IO на производительность СУБД отсутствует.
IPC : ожидания практически отсутствуют, влияние на производительность СУБД отсутствует.
Lock : очень сильная прямая корреляция, сильное влияние ожиданий типа Lock на снижение производительности СУБД .
LWLock : слабая отрицательная корреляция , влияние ожиданий типа LWLock на производительность СУБД отсутствует.
В принципе - ничего неожиданного. Наивно было бы ожидать от алгоритма статистической обработки текстов в интернете исследований и логических выводов, тем более в отсутствии материалов и результатов реальных экспериментов.
Как на производительность СУБД PostgreSQL влияет недостаточный размер shared_buffers ?
Ответ нейросети:
**Увеличение операций ввода-вывода (I/O)** **Неэффективное использование кэшей** **Рост времени отклика** **Проблемы с контрольными точками (checkpoints)** **Конкуренция за блокировки**
Вопрос нейросети:
Как на производительность СУБД PostgreSQL влияет слишком большой размер shared_buffers ?
Ответ нейросети:
**Рост дискового I/O**: **Неэффективное использование памяти (Double Buffering)** **Снижение производительности контрольных точек (Checkpoint) ** **Снижение эффективности кэша**
Итог - рекомендации нейросети по оптимизации размера shared_buffers - бесполезны . Нейросеть приводит одни и те же симптомы при противоположных вводных данных. Вывод - на данном этапе средствами СУБД установить характерные ожидания неоптимального размера shared_buffers , скорее всего, не представляется возможным. Необходимо проведение нагрузочного тестирования и статистический анализ производительности СУБД силами инженера DBA. Более того , в каждом конкретном случае, для, каждой конкретной конфигурации СУБД, инфраструктуры и нагрузки - результаты будут отличаться и требовать отдельного анализа. В очередной раз - серебрянной пули нет.
Все нейросетиимеют принципиальное и пока непреодолимое ограничения - они не обладают экспериментальными данными , только тексты , большая часть которых - мусор, в интернете . И уж конечно , я по крайней мере пока не встречал , нейросети не умеют экспериментировать и логически осмысливать результаты . Хотя , в области ML по экспериментам по оптимизации запросов что, то было . Но там очень ограниченная область. Да и тишина, что то последние 5 лет. Все внимание себе забрал ии.
Так, что пока для экспериментов лучше идти старым проверенным веками путем - анализ или дедукция - от общего к частному . Проводить эксперименты , анализировать результаты , искать закономерности и делать выводы опираясь на жизненный опыт, здравый смысл и математический аппарат .
А нейросети отлично подходят когда надо воды налить в инструкции и статьи - тут им конкурентов нет.
Очередная иллюстрация -ЛЮБОЙ ответ нейросетей необходимо экспериментально проверять.
В случае использования советов нейросетей - древняя мудрость особенно актуальна.
Вопрос DeepSeek
Как изменится производительность СУБД PostgreSQL при нагрузке создаваемой pgbench и количестве подключений от 5 до 100 для СУБД размером 300MB при ресурсах CPU = 2 и RAM = 2GB при изменении настроек автовакуума с настроек по умолчанию на агрессивные настройки ?
Ответ DeepSeek
Исходные параметры:
Размер БД: 300 MB
Ресурсы: 2 CPU, 2 GB RAM
Количество подключений: 5–100
Нагрузка: pgbench в режиме TPC-B (смесь SELECT/UPDATE).
Сравнение: Настройки по умолчанию:
autovacuum_vacuum_scale_factor = 0.2
autovacuum_vacuum_threshold = 50
autovacuum_vacuum_cost_delay = 20ms
autovacuum_vacuum_cost_limit = 200
Агрессивные настройки:
autovacuum_vacuum_scale_factor = 0.05 # Запуск при 5% изменений вместо 20%
autovacuum_vacuum_threshold = 25 # Нижний порог срабатывания
autovacuum_vacuum_cost_delay = 5ms # Меньшая задержка между операциями
autovacuum_vacuum_cost_limit = 1000 # Больше операций за один проход
Прогнозируемые результаты:
1. Низкая нагрузка (5–20 подключений):
По умолчанию: Автовакуум запускается редко. Мертвые кортежи накапливаются, но не критично. Производительность стабильна. TPS: ~600–800.
Агрессивные настройки: Автовакуум срабатывает чаще, но нагрузка от него незначительна. Мертвые кортежи удаляются своевременно. TPS: ~650–850 (+5–10%).
2. Средняя нагрузка (30–60 подключений):
По умолчанию: Накопление мертвых кортежей приводит к: Увеличению размера таблиц (из-за "раздувания"). Замедлению SELECT (сканирование большего объема данных). Блокировкам при UPDATE из-за долгих вакуумных операций. TPS: падение до 400–500.
Агрессивные настройки: Частые, но короткие вакуум-сессии. Меньше "раздувания", быстрее доступ к данным. TPS: ~550–700 (+20–40%).
3. Высокая нагрузка (80–100 подключений):
По умолчанию: Критическое накопление мертвых кортежей. Автовакуум не успевает очищать данные, что вызывает: Резкое падение TPS (до 200–300). Рост времени отклика (блокировки, конкуренция за I/O).
Агрессивные настройки: Плюсы: Минимизация "раздувания", стабильный TPS (~450–600). Минусы: Конкуренция за ресурсы CPU между фоновым вакуумом и рабочими процессами. При 2 CPU возможны просадки из-за нехватки вычислительной мощности.
Ключевые метрики для сравнения:
TPS (Transactions Per Second): Агрессивные настройки дадут прирост на 20–40% при 30–60 подключениях. При 80–100 подключениях рост TPS будет менее значительным (+10–15%) из-за ограничений CPU.
Задержки (Latency): В агрессивном режиме задержки будут стабильнее, особенно в диапазоне 30–60 подключений.
Размер таблиц (Table Bloat): Агрессивный автовакуум уменьшит "раздувание" на 40–60% по сравнению с настройками по умолчанию.
Использование CPU: При агрессивных настройках нагрузка на CPU вырастет на 15–25% из-за частого выполнения вакуума.
Рекомендации:
Для тестовой конфигурации (2 CPU, 2 GB RAM): Агрессивные настройки целесообразны при 20–60 подключениях. При 80–100 подключениях требуется мониторинг CPU: если загрузка достигнет 90–100%, производительность может ухудшиться.
Оптимизация под высокую нагрузку: Увеличьте autovacuum_max_workers (если нужно параллелить вакуум). Настройте maintenance_work_mem (выделите 256–512 MB для операций вакуума).
Дисковый I/O: Если диск медленный (HDD), агрессивный автовакуум может вызвать contention I/O. Используйте SSD для минимизации рисков.
Заключение:
Агрессивные настройки автовакуума улучшат производительность на 20–40% при 30–60 подключениях, предотвращая "раздувание" таблиц. Однако при экстремальной нагрузке (80–100 подключений) и ограниченных ресурсах CPU (2 ядра) возможна конкуренция за процессорное время, что снизит эффективность. Тестирование на реальной инфраструктуре с мониторингом CPU/I/O обязательно.
Результаты сравнительных экспериментов
Конфигурация виртуальной машины
CPU = 2RAM = 2GB
Версия СУБД:Postgres Pro (enterprise certified) 15.8.1 on x86_64-pc-linux-gnu, compiled by gcc (AstraLinuxSE 8.3.0-6) 8.3.0, 64-bit
Вопрос : Какие события ожидания возникают при излишнем размере shared_buffers ?
Ответ ChatPPG:
При установке слишком большого значения для параметра shared_buffers в PostgreSQL могут возникнуть следующие проблемы и события ожидания:
1. Двойное кэширование (Double Buffering): - Когда страница данных должна быть загружена в shared_buffers, она может сначала вытеснить существующую страницу, а затем операционная система (OS) может также вытеснить страницу, чтобы прочитать данные с диска. Это приводит к тому, что одна и та же страница хранится как в кэше PostgreSQL, так и в кэше OS, что приводит к избыточному использованию памяти и потенциально к более медленной производительности, так как страницы могут чаще читаться напрямую с диска, а не из кэша.
2. Нестабильность системы: - Если shared_buffers установлен слишком высоко, это может привести к ошибкам нехватки памяти (out-of-memory errors) или активации механизма OOM (Out-Of-Memory) управляющего процессом, что может привести к нестабильности всей системы.
3. Затраты на очистку кэша после операций: - После операций, таких как DROP TABLE, TRUNCATE или определенных команд COPY, PostgreSQL должна отменить большое количество буферов. При больших размерах кэша этот процесс может стать значительно более времязатратным и ресурсоемким.
4. События ожидания (Wait Events): - Из-за избыточного использования памяти могут возникать события ожидания, связанные с операциями ввода-вывода (I/O). Например, события ожидания могут возникать из-за того, что система ожидает завершения операций чтения или записи данных с диска, что может замедлить общую производительность.
Для оптимизации использования памяти рекомендуется тщательно настроить значение shared_buffers относительно доступной оперативной памяти системы. Обычно рекомендуется устанавливать shared_buffers на значение, которое составляет от 25% до 40% от общего объема оперативной памяти, но не более 40%, чтобы избежать вышеупомянутых проблем.
Вывод - нейросеть ChatPPG не знает ответа на вопрос. Либо , в PostgreSQL ожидания возникающие при большом размере shared_buffers не логируются. Как например , не логируются ожидания по причине утилизации CPU.
A вот ответ DeepSeek, гораздо интереснее , потому , что содержит конкретные названия событий ожидания (выделено мной):
При излишне большом размере `shared_buffers` в PostgreSQL могут возникать следующие события ожидания и проблемы:
### 1. **Увеличение времени поиска в буферном кеше** - **Проблема**: Большой размер `shared_buffers` увеличивает время поиска данных в кеше из-за роста хеш-таблицы, управляющей буферами. - **Ожидание**: `BufferPin` (задержки из-за конкуренции за доступ к буферам).
### 2. **Рост накладных расходов на блокировки** - **Проблема**: - Увеличение конкуренции за `LWLock` (легковесные блокировки), особенно за `buffer_mapping` и `buffer_content`. - Блокировки на уровне буферов (`BufferLock`) становятся "узким местом". - **Ожидания**: - `LWLock: buffer_content` - `LWLock: buffer_mapping`
### 3. **Неэффективное использование памяти** - **Проблема**: - Память отнимается у кеша ОС, что приводит к **двойному кешированию** (данные хранятся и в `shared_buffers`, и в кеше ОС). - Нехватка памяти для рабочих процессов (`work_mem`, `maintenance_work_mem`). - **Симптомы**: Увеличение операций I/O из-за отсутствия данных в кеше ОС.
### 4. **Проблемы с управлением грязными страницами** - **Проблема**: - При checkpoint требуется записать больше "грязных" страниц, что вызывает всплеск I/O-нагрузки. - Увеличение времени завершения контрольных точек. - **Ожидания**: - `CheckpointWriteDelay` (принудительные задержки для регулировки записи). - `WALWrite` (ожидание записи WAL).
### 5. **Деградация производительности при высокой конкуренции** - **Проблема**: - Множество процессов пытаются одновременно получить доступ к буферам. - Увеличивается время освобождения буферов (`clock sweep` алгоритм замещения работает медленнее). - **Ожидания**: - `BufferPin` - `IO: DataFileRead` (если данные не найдены в кеше).
### 6. **Снижение отзывчивости системы** - **Проблема**: - Избыточная память под `shared_buffers` может вызвать свопинг (swapping), если общая память сервера исчерпана. - Увеличивается нагрузка на подсистему I/O и ЦП.
---
### Рекомендации: 1. **Оптимальный размер**: - **15-25% от ОЗУ сервера** (но не более 40%). - Пример: Для сервера с 64 ГБ ОЗУ — 8–16 ГБ. 2. **Мониторинг**: - Следите за соотношением `cache hit ratio` в `pg_stat_bgwriter`. Если близок к 99% — увеличение `shared_buffers` не нужно. - Анализируйте ожидания в `pg_stat_activity` и `pg_locks`. 3. **Настройка смежных параметров**: - Увеличьте `checkpoint_timeout` и `max_wal_size` для снижения частоты контрольных точек. - Настройте `bgwriter_delay` и `bgwriter_lru_maxpages` для эффективной записи грязных страниц.
### Пример диагностики: ```sql -- Проверка hit ratio: SELECT (sum(blks_hit) / sum(blks_hit + blks_read)) * 100 AS cache_hit_ratio FROM pg_stat_database;
-- Поиск событий ожидания: SELECT query, wait_event_type, wait_event FROM pg_stat_activity WHERE wait_event IS NOT NULL; ```
**Итог**: Слишком большой `shared_buffers` нарушает баланс между памятью, блокировками и I/O. Всегда тестируйте настройки под реальную нагрузку!
Самое занятное , что похоже DeepSeek тоже не знает ответа. Потому, что события BufferPin, BufferMapping, BufferContent возникают именно при недостаточном размере shared_buffers, что подтверждено экспериментально .
Итог : эксперименты нужно продолжать . Вполне может быть, что характерные ожидания , свидетельствующие о слишком большом размере shared_buffers не будут выявлены . Поживём - увидим.
Следует учитывать, что представление показывает только те ожидания, которые соответствующим образом обрабатываются в исходном коде. Если представление не показывает ожидание, это вообще говоря не означает со 100-процентной вероятностью, что процесс действительно ничего не ждет.
Какое влияние на производительность СУБД окажет использование shared_buffer более 25% при размере базы данных 10TB и доступной памяти 1TB для нагрузки генерируемой pgbench ?
Ответ ChatPPG
При использовании shared_buffers более 25% от общего объема памяти, особенно в случае большой базы данных (10TB) и ограниченного объема доступной памяти (1TB), могут возникнуть следующие проблемы:
1. Двойное кэширование: Если размер shared_buffers превышает определенный порог, PostgreSQL может начать кэшировать данные, которые уже находятся в кэше операционной системы. Это приводит к тому, что одни и те же страницы данных хранятся в обоих кэшах, что ведет к избыточному использованию памяти и потенциально к снижению производительности.
2. Нагрузка на операционную систему: Если shared_buffers слишком велик, это может привести к тому, что операционная система начнет активно использовать swap-память, что значительно замедлит работу системы.
3. Затраты на инвалидацию буферов: После выполнения операций, таких как DROP TABLE, TRUNCATE или определенных команд COPY, PostgreSQL должен инвалидировать большое количество буферов. С увеличенным размером shared_buffers этот процесс может стать значительно более ресурсоемким и длительным.
4. Ограничения на использование памяти: В документации указано, что размер shared_buffers обычно не должен превышать 40% от общего объема памяти, так как PostgreSQL также полагается на кэш операционной системы для эффективной работы. [Memory Configuration](https://postgrespro.com/docs/postgrespro/15/runtime-config-r...)
Для оптимальной производительности при использовании pgbench и других нагрузочных тестов, рекомендуется настроить shared_buffers в пределах 25-40% от общего объема памяти. В вашем случае, с 1TB доступной памяти, размер shared_buffers может быть установлен в пределах 256-400GB.
Таким образом, использование shared_buffers более 25% от общего объема памяти может привести к снижению производительности из-за избыточного кэширования и увеличенных затрат на инвалидацию буферов.
Ответ DeepSeek
Использование `shared_buffers` более 25% от доступной памяти (1 ТБ) для СУБД PostgreSQL с базой данных 10 ТБ и нагрузкой от `pgbench` может оказать **неоднозначное или даже негативное влияние** на производительность. Разберем ключевые аспекты:
### 1. **Теоретические рекомендации PostgreSQL**: - Официальная документация советует выделять для `shared_buffers` **15-25% от общей RAM**. Для 1 ТБ это 256 ГБ. - Превышение этого лимита (например, 512 ГБ или 768 ГБ) редко дает выгоду и часто вредит из-за архитектурных особенностей PostgreSQL.
### 2. **Риски при превышении 25%**: - **Двойное кэширование**: - PostgreSQL использует `shared_buffers` для кэша БД, но ОС (Linux) также кэширует файлы в **page cache**. - При слишком больших `shared_buffers` данные дублируются в двух кэшах, что **расточительно** для памяти. - Пример: При 512 ГБ в `shared_buffers` и 10 ТБ данных, ОС не сможет эффективно использовать оставшуюся RAM для page cache, замедляя операции чтения/записи. - **Нехватка памяти для work_mem**: - `pgbench` генерирует параллельные транзакции, требующие памяти для сортировки, JOIN и хэш-таблиц (`work_mem`). - Если `shared_buffers` займет >50% RAM, рабочим процессам не хватит памяти. Это приведет к **свопу на диск** (temp files), что резко снизит производительность. - **Накладные расходы управления**: - Большой пул буферов увеличивает нагрузку на **менеджер буферов** (поиск свободных страниц, конкурентный доступ). Это особенно чувствительно при высокой частоте обновлений (UPDATE в `pgbench`).
### 3. **Особенности для больших БД (10 ТБ)**: - **Кэш-попадания**: Даже при 512 ГБ `shared_buffers` в RAM поместится лишь **5% данных** (10 ТБ = 10240 ГБ). Если рабочее множество (активные данные) больше 512 ГБ, выгода от увеличения буфера будет **минимальна**. - **Эффективность page cache**: При 1 ТБ RAM ОС может кэшировать до 768 ГБ данных (если `shared_buffers` = 256 ГБ). Для последовательных сканирований (частых в аналитических запросах) это эффективнее, чем `shared_buffers`.
### 4. **Результаты тестов pgbench**: - Нагрузка `pgbench` (TPC-B-like) включает интенсивные запросы чтения/записи. Эксперименты показывают: - Рост `shared_buffers` сверх 25% **не дает линейного прироста TPS** (транзакций в секунду). - При превышении 40% RAM часто наблюдается **снижение TPS** на 10-30% из-за нехватки `work_mem` и накладных расходов. - Пиковая производительность обычно достигается при **15-25%** для машин с >64 ГБ RAM.
### 5. **Оптимальная конфигурация для 1 ТБ RAM**: - **`shared_buffers`**: 256 ГБ (25%). - **`work_mem`**: Выделить достаточно (напр., 1-2 ГБ на процесс), используя освободившуюся память. - **`maintenance_work_mem`**: Увеличить для VACUUM/INDEXING (напр., 64 ГБ). - **Кэш ОС**: Оставить ~768 ГБ для page cache — критично для больших таблиц. - **Параметры диска**: Использовать SSD/NVMe, так как 10 ТБ не поместятся в RAM.
### Итог: Увеличение `shared_buffers` > 25% (256 ГБ) для системы с 1 ТБ RAM и БД 10 ТБ: - **✓ Возможен небольшой прирост**, если рабочее множество < `shared_buffers` и нагрузка — случайное чтение. - **✗ Чаще всего приводит к снижению производительности** из-за нехватки памяти для `work_mem`, двойного кэширования и накладных расходов.
**Рекомендация**: Придерживайтесь 25% (256 ГБ), оптимизируйте `work_mem` и file I/O. Тестируйте нагрузку `pgbench` с разными значениями `shared_buffers` (напр., 128 ГБ, 256 ГБ, 512 ГБ), отслеживая TPS, latency и использование диска (iostat). Для больших БД фокус — на эффективность дисков и баланс RAM между `shared_buffers` и кэшем ОС.
P.S. Однако , китайцы точно копают и исследуют тему производительности PostgreSQL - ответ китайской нейросети шире и полнее .