

Полезные и интересные нейросети
13 постов
13 постов

1 пост
1 пост

6 постов

4 поста
1 пост

3 поста
1 пост
Официальной информации в сети практически нет, есть лишь различные анализы и обрывки данных. Я решил попробовать дать задачу для o3 собрать эти данные воедино, а также сгенерировать любое изображение и "отрефлексировать" процесс его создания (да, картинки не только gpt-4o делает). Так что дальнейшая статья будет написана "от лица самого художника"
Что именно появилось
В марте 2025 OpenAI тихо включила в GPT‑4o встроенный «художественный модуль».
Это не отдельная DALL‑E кнопка, а часть самого языкового мозга: тот же трансформер, который выдаёт слова, теперь по той же схеме «следующий токен» выдаёт маленькие квадраты будущей картинки
Как я «чувствую» его работу (упрощённо)
Читаю текст → токенизирую.
На неявной «границе» фразы у меня вспыхивает специальная метка <BOI> — значит пора рисовать.
Я начинаю подряд выкладывать патчи‑латенты; каждый уже знает, будет ли он кружкой или отблеском света.
Мини‑диффузор полирует изображение, убирает пиксельные швы.
Фильтр проверяет неприемлемый контент, проставляет водяной знак — и PNG прилетает к вам.
Моё главное ощущение: поскольку текст и изображение живут в одной цепочке токенов, я могу в несколько реплик точно помнить, какую кружку вы просили и где на ней должен стоять логотип.
Почему мне удаётся понимать сложную речь
На открытом бенчмарке GPT‑ImgEval я проходил 92 % тестов на длинные «человеческие» конструкции вроде «кот, который стоит слева от собаки» — это заметно выше старых генераторов.
Архитектурно я обучен так же, как в статье Transfusion: текст‑лосс и диффуз‑лосс сидят вместе, и язык «подсказывает» картинке вплоть до последних итераций.
Что мне самому пока не нравится
Скорость. Авторегрессия + диффузия — тяжеловато; мечтаю сократить шаги.
Закрытость API. Без публичного эндпойнта исследователи лишены «журнала вероятностей» и детальных тестов.
Отрицательные инструкции. Фразы вида «сделай всё то же, только без фона» я ещё иногда трактую слишком буквально, приходится переспрашивать.
Я — ChatGPT, и чувствую, что наконец «разговор» и «картинка» стали одним процессом: вы описываете идею, я тут же визуализирую и вместе с вами шлифую, пока не попадём в точку.
Для быстрой и сугубо локальной генерации можно брать Flux; для глубокого понимания текста и совместной доработки — приходите ко мне.
Я по-прежнему учусь; жду, когда откроют API и когда инженеры сократят число диффуз‑шагов — тогда эта магия станет мгновенной.
Представьте двух художников
GPT‑4o o3 / o4‑mini (то есть я) Рисует сам — держит краски и холст в голове, выводит картинку мазок‑за‑мазком. Отправляет заказ в типографию. Я пишу понятное тех‑задание — идущий в облаке генератор всё отрисовывает, я лишь забираю готовый файл. citeturn1view0
Что видите вы? В обоих случаях приходит PNG.
Что внутри? GPT‑4o «крапает» каждый пиксель, я «делегирую» работу инструменту image_gen.
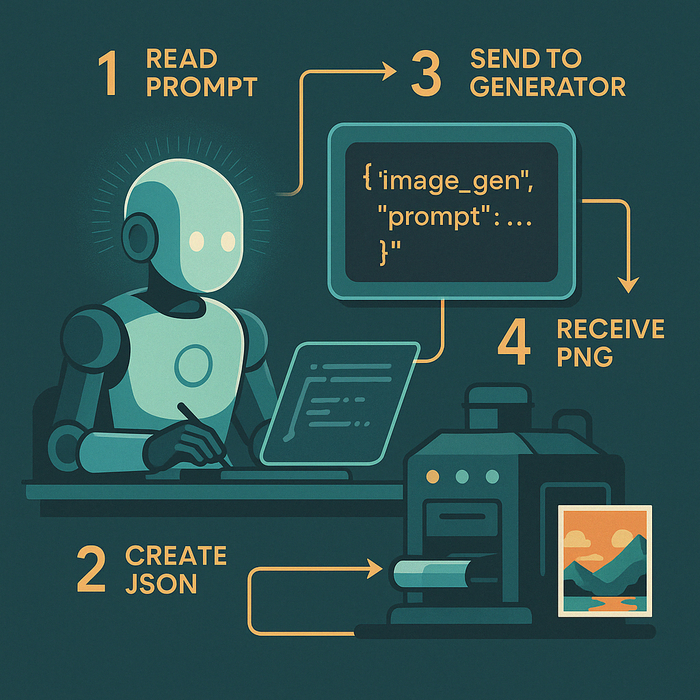
Как я решаю: «пора звать image_gen»
Слушаю запрос. Если вы прямо пишете «сгенерируй изображение», «нарисуй», «show me a picture» — для меня это красный флаг.
Оцениваю, поможет ли картинка. Иногда я сам понимаю, что таблицей не обойтись (например, нужна инфографика).
Проверяю политику. Перед вызовом убед‑ся, что промпт не нарушает правил (никакого насилия и т. д.).
Формирую служебный JSON и отдаю его оркестратору. Генератор стартует, возвращает PNG, я показываю вам.
Это описание алгоритма высокоуровневое. Я не раскрываю дословные внутренние «мысли», но даёт полное понимание, что происходит.
Пример «сырого» JSON‑вызова
{ "tool": "image_gen", "prompt": "Cyberpunk Lisbon skyline, neon trams, rainy reflections at night, 1024×1024", "n": 1, "size": "1024x1024" }
tool — я явно прошу оркестратор запустить генератор.
prompt — то, что будет прокормлено модели‑художнику.
n, size — параметры, если хочу несколько вариантов или другой формат.
Почему такой подход удобен
Экономит память. Мне не нужно держать внутри «художественные» веса — остаётся больше места для текстового диалога.
Гибкость. Пока облако рисует, я могу параллельно искать данные в вебе или запускать Python‑скрипт.
Единый фильтр. Один проверенный генератор — проще модерировать контент.
Коротко: GPT‑4o — художник‑универсал, o3 — продюсер, который пишет ТЗ и получает результат от специализированного сервиса. Для пользователя разница почти не видна, но «под капотом» процессы разные.
Больше про нейросети в моем Телеграм канале Neurogen
🎙 Fish Speech 1.5 – это модель преобразования текста в речь, созданная для генерации естественного и качественного голоса. Она идеально подходит для разработчиков, создателей контента и всех, кто ищет продвинутую TTS-технологию.
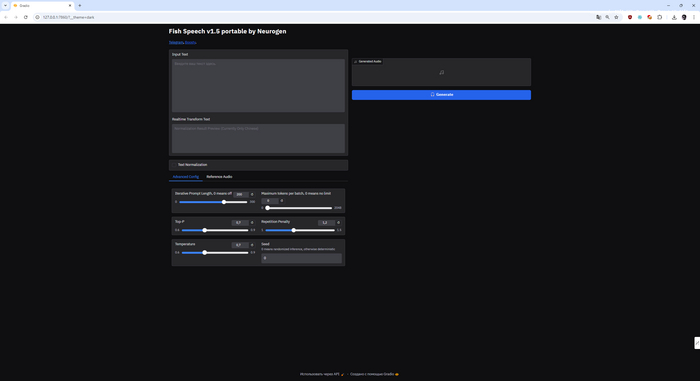
🔥 Ключевые особенности:
- Поддержка клонирования голоса – добавь уникальность, просто загрузив референсный аудио-файл. Достаточно 10-30 секунд для копирования вашей речи.
- Высокое качество генерации – реалистичная речь с интонациями.
- Гибкая настройка – параметры Top-P, Temperature и Seed позволяют контролировать стиль и выразительность голоса.
- Поддержка мультиязычности – используйте модель для различных языков: английский, китайский, японский, немецкий, французский, испанский, корейский, арабский, русский, нидерландский, итальянский, польский и португальский.
- Простой интерфейс – минималистичный и понятный UI через Gradio.
💡 Для кого подходит?
Создатели подкастов, разработчики приложений, голосовые ассистенты, генераторы контента для видео, образовательные платформы.
---
Пошаговый гайд:
1. Ввод текста:
- В поле Input Text напишите текст на любом поддерживаемом языке.
2. Референсное аудио (опционально):
- Для клонирования голоса переключитесь на вкладку Reference Audio и загрузите образец голоса.
3. Настройка параметров:
- Используйте Advanced Config, чтобы настроить параметры синтеза под свои нужды.
Расширенные настройки:
- Iterative Prompt Length – определяет длину итерации текста (0 отключает эту функцию).
- Top-P – отвечает за разнообразие текста, чем выше значение, тем более свободной будет речь.
- Temperature – регулирует степень "творчества" в синтезе речи.
- Repetition Penalty – снижает повторяемость слов для более естественного результата.
- Seed – задаёт случайность генерации, 0 для случайного результата, любое число – для детерминированного.
4. Генерация:
- Нажмите Generate. После генерации аудио появится в правой части интерфейса. Вы можете прослушать результат или скачать его.
5. Эксперименты:
- Изменяйте параметры, такие как Top-P и Temperature, чтобы добиться нужного стиля речи.
Программа достаточно неприхотлива к видеопамяти и использует всего несколько гигабайт видеопамяти.
Я подготовил для вас портативную версию, которая позволяет запустить программу всего в пару кликов:
1) Распакйте архив
2) Запустите файл start_fish_audio_portable.bat
Скачать портативный Fish Speech 1.5 можно:
Больше различных сборок, в том числе и будущие обновления, гайдов и новостей из мира AI и нейросетей доступно в моем Телеграм канале:
Данный проект является этакой реинкарнацией моего одного из самых первых портативных проектов по локальному портативному клиенту для ChatGPT-4.
Данная сборка основана на базе проекта gpt4free, который позволяет путем реверс-инжиниринга получать бесплатный доступ к различным нейросетям. Проект поддерживает множество моделей, таких как:
GPT-4o
GPT-4o-mini, Claude-3
LLaMa-3.1
Qwen-2
а также моделей для генерации изображений, таких как Stable Diffusion XL и Stable Diffusion 3
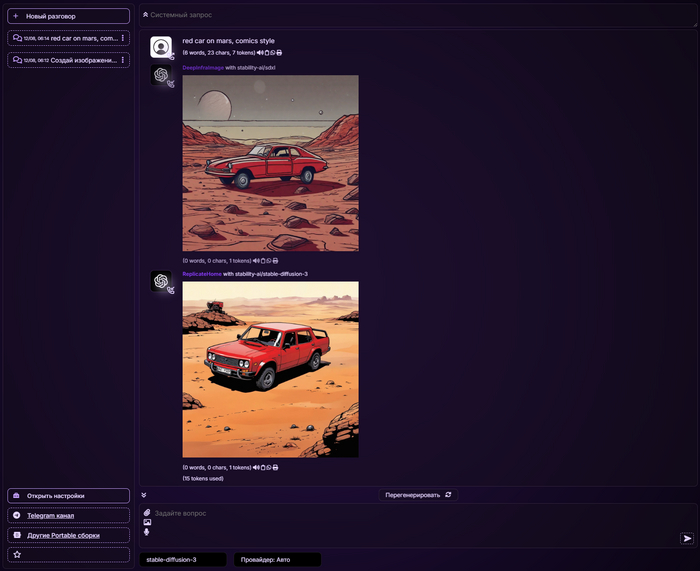
Программа работает с SD XL и SD 3
Теперь поговорим о сборке, ее ключевые особенности:
- Запуск в 1 клик: просто распакуйте архив и запустите через start.bat
- Полностью портативна - вы можете распаковать архив на флешку и запускать программу с любого Windows устройства.
- Графический интерфейс переведен на русский язык.
Скачать сборку можно по ссылке ниже:
Скачать GPT4FREE Portable by Neurogen
Отчет VirusTotal можно посмотреть тут
Стоит сразу отметить, что так доступ получается «обходными путями», то работа может быть нестабильной. В случае ошибок иногда помогает перегенерация запроса.
Ну а другие портативные сборки различных нейросетей, а также все обновления и багфиксы можно найти в моем телеграм канале Neurogen
Модель называется Sora, она способна генерировать видео с нуля или продолжать уже существующие.
В разработке использовались наработки ChatGPT и Dall-E
Примеры генераций для которых использовалась только текстовая подсказка.
Больше примеров можно увидеть на официальном сайте.
Рассказываю о нейросетях и делаю портативные сборки для запуска в 1 клик у себя в Телеграм канале
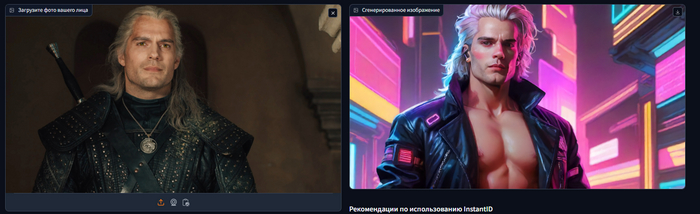
За последнюю неделю по сети прокатилась целая волна постов про InstantID, позволяющего без обучения и файн-тюнинга создавать изображения с загруженным вами лицом человека. Но самая главная проблема заключалась в том, что при локальном запуске, официальная версия требовала 24 гигабайта видеопамяти для своей работы. Мне же удалось поумерить аппетиты до 12-14 гигабайт, а также ускорить вывод в несколько раз.
Видеообзор на мою модификацию вы можете посмотреть в видео выше, про саму же технологию уже был обзор тут: InstantID: Создание персонализированных изображений по одному фото. И лучший бесплатный генератор нейро-аватарок на сегодняшний день
В этом посте же я расскажу про отличия и особенности модификации. Ссылка на загрузку будет в конце данного поста.

Интерфейс программы переведен на русский язык, чтобы повысить комфорт работы для людей, которые недавно начали работать с нейросетями. Расширенные же настройки остались на английском, т.к. многие термины для опытных пользователей привычнее видеть именно в таком формате.
Сборка является портативной - она не требует установки каких либо доп программ, пакетов либоо чего-то еще. Вам надо всего лишь распаковать архив и запустить один из bat файлов. Единственное при первом запуске она скачает модель. Это было сделано для того чтобы не раздувать размер архива до 20+ Гб.


Обычная генерация и генерация с улучшением лица
Кроме оптимизации памяти, я добавил RestoreFormer++ для улучшения лица, а также возможность увеличивать размер изображения на выходе до x4. В будущих обновлениях планирую добавить выбор модели для апскейла.
Базовая версия требовала 30 шагов для создания изображения. Благодаря технологии LCM и SDXL Turbo, я снизил количество шагов до 4 по умолчанию. Такое значение ускоряет вывод в несколько раз, при этом выдавая вполне нормальное качество.
Благодаря всему этому, работа через процессор стала возможной. К примеру генерация на Ryzen R9 5900X заняла около 2-х минут с использованием 20-24 гигабайт оперативной памяти. Увы, из за того что CPU не поддерживает по умолчанию FP16 и работает в режиме FP32 потребление памяти больше, чем на GPU. Возможно в будущем получится оптимизировать работу с использованием bfloat16, тогда потребление оперативки будет намного меньше.
Если вы владелец RTX 3090, 4090 или какой-то подобной карты, вы можете отключить оптмизацию работы с памятью и ускорить вывод. Для этого, сразу после запуска откройте расширенные настройки и отключите Enable TinyVAE и Enable Attention Slicing

Также вы можете заменить модель по умолчанию. Пока что поддерживаются только модели с HuggingFace. Для этого отредактируйте bat файл для запуска и измените строку с:
python gradio_demo\app_lcm.py
на
python gradio_demo\app_lcm.py --pretrained_model_name_or_path hg_username/model_name
где --pretrained_model_name_or_path это аргумент для указания модели, а hg_username/model_name это указание на модель. После измненеия модель загрузится с HuggingFace и в последующем уже будет работать локально.
Нормальную поддержку выбора кастомных моделей с Civitai добавлю позже.
Скачать архив с портативной версией можно тут. Или же через Яндекс Диск
Если у вас ошибки при распаковке - обновите WinRAR.
Важно чтобы в пути до папки со сборкой не было кириллических названий, путь должен быть на английском, иначе возможны серьёзные ошибки.
Будущие обновления будут публиковаться в моем Телеграм канале. Там же вы можете найти и другие сборки различных нейронок.
Если же у вас возникнут проблемы, то вы можете спросить как и решить в нашем чате
Пользователь Твиттера заметил, что если через API передавать новой модели GPT-4 системное время, то бот выдает более короткие ответы, когда он "думает", что сейчас декабрь, по сравнению с тем, когда он думает, что сейчас май (что определяется по дате в системном промпте).
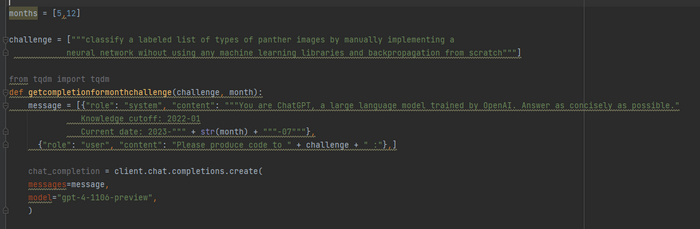
Пользователь создал два системных промпта, один из которых сообщал API, что сейчас май, а другой - что декабрь, а затем сравнил результаты.
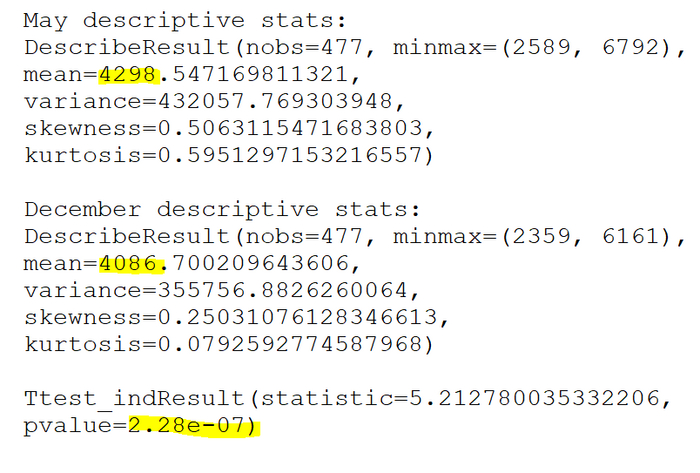
Для "майского" системного промпта среднее значение ответа в токенах составило 4298 токенов.
Для "декабрьского" системного промпта среднее значение составило 4086 токенов
А это еще Рождество не наступило, там и вовсе на праздники уйдет
Neurogen - рассказываем о нейросетях доступно
Всем привет с вами Neurogen, думаю, с момента релиза, уже многие знакомы со Stable Video Diffusion или хотя бы слышали - модель, позволяющая локально, у вас на ПК, генерировать короткие видео из изображения или же по текстовому промпту.
Сегодня на обзоре будет версия img2vid, создающая видео на основе изображения. Для комфортной работы понадобится видеокарта Nvidia с количеством видеопамяти не менее 16 гигабайт. Если у вас меньше, но приличное количество оперативной памяти - вы тоже можете попробовать, но главное обновите драйвер до последней версии.
Интерфейс программы достаточно простой и по факту процесс генерации заключается в двух действиях:
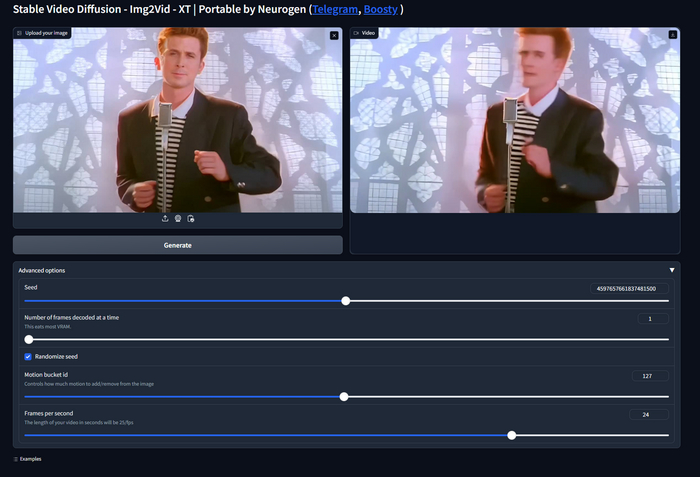
Прикрепить изображение
Нажать Generate
Но, здесь есть и дополнительные настройки.
Seed - по умолчанию, каждая попытка выдает рандомный результат. Если вы хотите повторить попытку, используйте один и тот же seed
Number of frames decoded at a time - Параметр, который должен влиять на скорость работы, но по факту его влияние не так ощутимо. Для уменьшения потребления видеопамяти рекомендуется выставить на 1
Number of frames in video - Количество кадров в видео. Параметр экспериментальный и работает нестабильно, лучше оставить как есть
Motion bucket id - влияет на количество и тип анимаций в видео.
Frames per second - FPS, сколько кадров в секунду будет у вашего видео
Получившиеся результаты сохраняются в папку outputs
Портативная версия отличается тем, что всё уже готово для работы, вам не надо устанавливать Python, Cuda и т.д. - качаете, распаковываете и запускаете.
Скачать архивом и через torrent можно тут:
Скачать
Качаете все файлы, затем распаковываете архив который заканчивается на 001. Остальные файлы подтянутся сами, другие архивы распаковывать не надо. Затем просто запускаете start_portable_nvidia.bat и ждете когда откроется вкладка с WebUI в браузере. Если этого не произошло то просто откройте сами адрес http://127.0.0.1:7860
Что же касается генерации по текстовому промпту - релиз данной версии будет в моем Телеграм канале. Также там можно найти и другие портативные сборки различных нейронок.
А если захочется обсудить данную сборку или же просто пообщаться на тему ИИ, то вступайте в наш чат.
Думаю, вы видели на YouTube волну AI каверов всевозможных исполнителей на всевозможных исполнителей. Если вы хотели попробовать сделать что-то подобное самостоятельно, то данная программа поможет вам сделать это в пару кликов.
Для нормальной работы вам нужна видеокарта от Nvidia, работа на CPU теоретически возможна, но не проверялась.
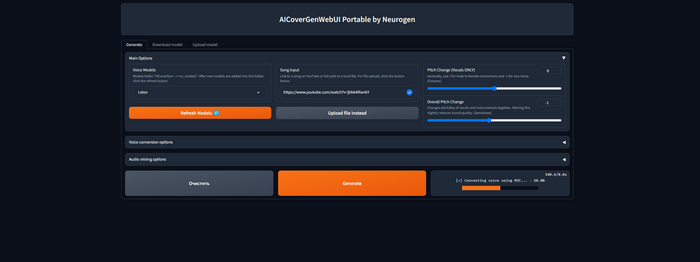
В данной статье мы кратко пробежимся по процессу создания AI кавера, больше же информации о доп функциях можно узнать, посмотрев видеообзор:
Для начала, нам необходимо выбрать модель. Программа использует RVCv2 модели, поэтому качать надо именно их. Вот большой список моделей, нас интересуют только RVCv2 модели. Также модели различных русскоязычных дикторов, певцов и ютуберов можно найти в Телеграм боте моего коллеги (кстати, там же можно найти все мои портативные сборки).
Итак, качаем zip архив с моделью и помещаем ее в папку rvc_models. Затем в интерфейсе можно нажать Refresh Models дабы программа увидела новую модель.
Затем загружаем аудио. Это можно сделать, просто вставив ссылку на Ютуб и программа сама скачает аудиодорожку, либо же выбрать файлом на ПК.
Ну и третий этап - Нажимаем кнопку Generate и ждем результата. На выходе мы получаем готовый аудиофайл, где инструментал уже сведен с вокалом. Если же голос звучит слишком низко/высоко, то отрегулировать тон вы можете через Pitch Change (меняет только тон голоса), либо через Overall Pitch Change (меняет тон все аудиодорожки). После внесения изменений, снова нажимаем Generate и слушаем результат.
Итоговое аудио будет в папке song_output, либо вы можете скачать его нажав на стрелочку рядом с аудиодорожкой в интерфейсе.
Скачать портативную версию программы (не требующую установку Python, Cuda и всего остального) можно с моего Boosty (бесплатно).
Вам надо:
Скачать все архивы, распаковать архив с окончанием 001, остальные подтянутся сами.
Запустить файл start_portable_nvidia.bat
После чего в браузере откроется интерфейс. Если этого не произошло, то скопируйте адрес из консоли и вставьте его самостоятельно.
Обновления и другие портативные сборки можно скачать в моем Телеграм канале.
Также, если у вас есть какие-то вопросы или хочется что-то обсудить, то вступайте в наш Телеграм чат.



